All you should know about translation equivariance/invariance in CNN
All you should know about translation equivariance/invariance in CNN
First published on Medium
Translation invariance and translation equivariance are two important concepts in convolutional neural networks (CNNs) related to the network’s ability to recognise objects regardless of their position within an image.

Translation invariance


Translation invariance means that a CNN is able to recognise an object in an image regardless of its location or translation within the image. In other words, the network’s output should remain the same even if the image is shifted or translated in any direction. This property is desirable because it allows the network to generalize well to different images of the same object with different translations.
Summary:
- Pooling layers help build shift invariance in convolutional networks.
- Shift invariance means that the same maximum value will be found under the pooling kernel even if the image is shifted slightly.
- However, this shift invariance is only locally true and may not hold if the image is shifted too much.
- Pooling is not completely bulletproof with regards to shift invariance, but it can still identify the same features in an image regardless of their position.
Translation equivariance
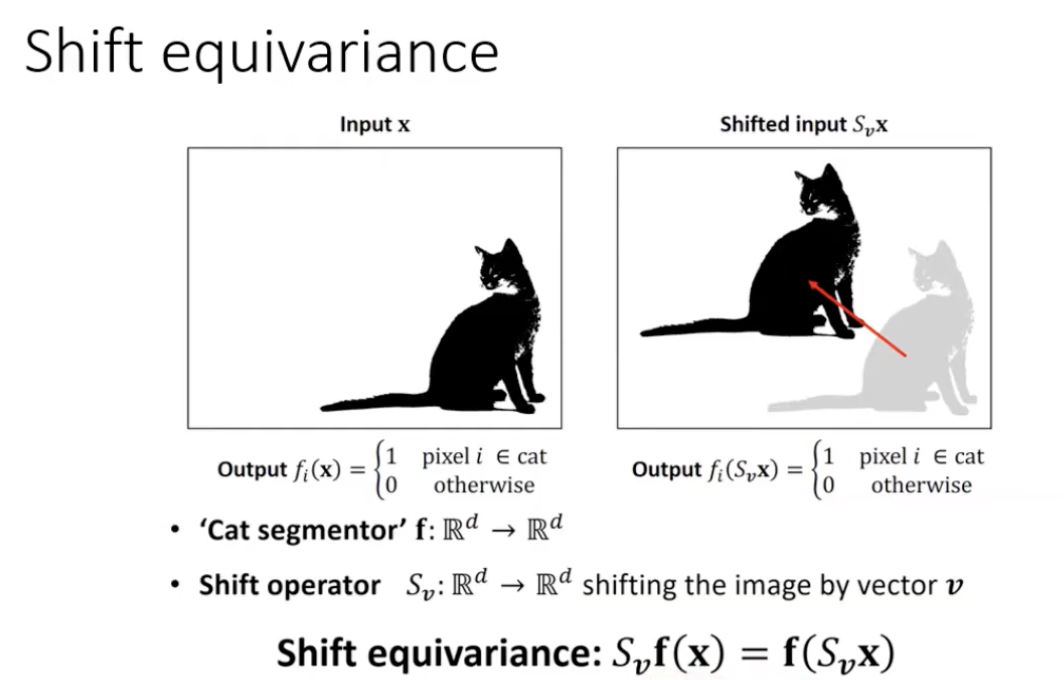
Translation equivariance, on the other hand, means that the network’s output is related to the location of the object within the image. More specifically, if the input image is shifted or translated, the output of the network will also be shifted or translated accordingly. This property is useful for tasks such as object detection, where the location of the object within the image is important.
In CNNs, translation invariance is achieved through the use of pooling layers, which aggregate feature maps into a more compact representation while preserving the most important features. Meanwhile, translation equivariance is achieved through the use of convolutional layers, which apply a filter or kernel to the input image to extract local features that are then combined to form a larger, more complex feature map. By using a combination of convolutional and pooling layers, CNNs are able to achieve both translation invariance and equivariance, making them highly effective for image recognition tasks.
Max Pooling breaks shift equivariance? — Try antialiaing
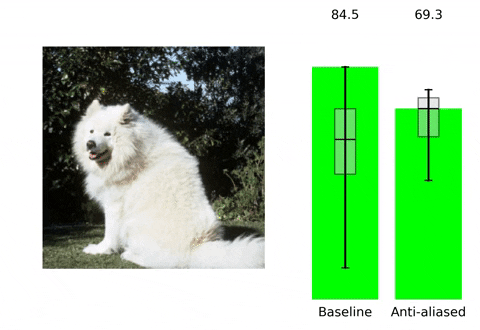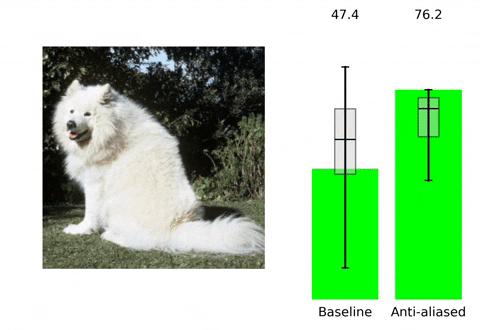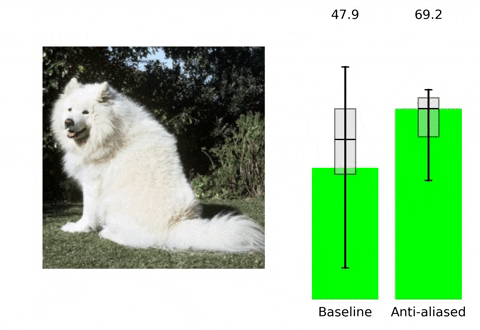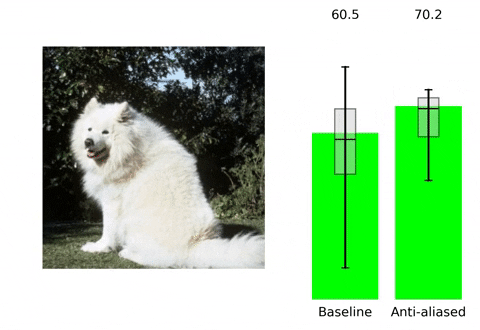
Convolutional neural networks (CNNs) are approximately shift equivalent through their convolutional layers. However, the use of Max Pooling layers can break shift equivariance (also known as translation equivariance). To address this issue, one solution is to use anti-aliasing techniques in Computer Vision, such as blurring the image and then down-sampling it. This technique can help preserve important features in the image while reducing the effect of minor shifts or translations, which in turn can improve the shift equivariance of the CNN.
You can check more in the paper

There is another research about Harmonic Networks: Deep Translation and Rotation Equivariance

CNN and Poorly shift invariant
Why do deep convolutional networks generalize so poorly to small image transformations?
Convolutional Neural Networks (CNNs) are commonly assumed to be invariant to small image transformations: either because of the convolutional architecture or because they were trained using data augmentation. Recently, several authors have shown that this is not the case: small translations or rescalings of the input image can drastically change the network’s prediction. In this paper, we quantify this phenomena and ask why neither the convolutional architecture nor data augmentation are sufficient to achieve the desired invariance. Specifically, we show that
- the convolutional architecture does not give invariance since architectures ignore the classical sampling theorem,
- and data augmentation does not give invariance because the CNNs learn to be invariant to transformations only for images that are very similar to typical images from the training set. We discuss two possible solutions to this problem: (1) antialiasing the intermediate representations and (2) increasing data augmentation and show that they provide only a partial solution at best. Taken together, our results indicate that the problem of insuring invariance to small image transformations in neural networks while preserving high accuracy remains unsolved.
There are also some interesting opinions from (Chinese Platform)
- It is precisely because pooling itself has weak translation invariance and will lose some information that in tasks that require translation equivariance (such as detection and segmentation), convolutional layers with a stride of 2 are often used instead of pooling layers.
- In many classification tasks, global pooling or pyramid pooling is often used at the end of the network to learn global features.
- The translation invariance that can be used for classification mainly comes from the parameters. Because of the translation equivalence of convolutional layers, this kind of translation invariance is mainly learned by the final fully connected layer, and it is more difficult for networks without fully connected layers to have this property.
- To summarize, the translation invariance of CNN mainly comes from data learning, and the structure can only bring very weak translation invariance, while learning relies on data augmentation.
Reference
- 05 Imperial’s Deep learning course: Equivariance and Invariance — YouTube
- What is translation equivariance, and why do we use convolutions to get it? | by Christian Wolf | Medium
- Making Convolutional Networks Shift-Invariant Again
- Harmonic Networks: Deep Translation and Rotation Equivariance
- Since CNN has translation invariance to images, will it be effective to use image translation (shift) for data augmentation to train CNN?